
Agentic RAG vs semantic RAG: why pins change AI retrieval
Traditional semantic RAG searches document chunks. Agentic pin-first RAG can cost more and take longer, but it fits Pindown's pin model by giving agents named, structured units to target, verify, update, and reuse.
Most AI workspaces eventually run into the same question: how does the agent find the right information?
The common answer is semantic RAG: split documents into chunks, create embeddings, search for similar text, and pass the best matches into the model. That is useful, especially for fixed datasets, archives, document snapshots, and slower-changing knowledge bases.
But continuously changing workspaces are different. If every change needs re-chunking, re-embedding, sync jobs, freshness rules, invalidation logic, and custom ranking, semantic RAG starts to feel like over-engineered glue.
That is the disadvantage of bolting AI onto existing structures. The underlying product was designed around pages, folders, docs, or databases, so the AI layer has to work hard to translate that structure into something an agent can act on.
Pindown's pin-first approach changes the retrieval target. Instead of asking the agent to find one sentence in a haystack, the workspace gives the agent structured pins it can target directly: a chart pin, a brief pin, a table pin, a decision pin, a roadmap pin.
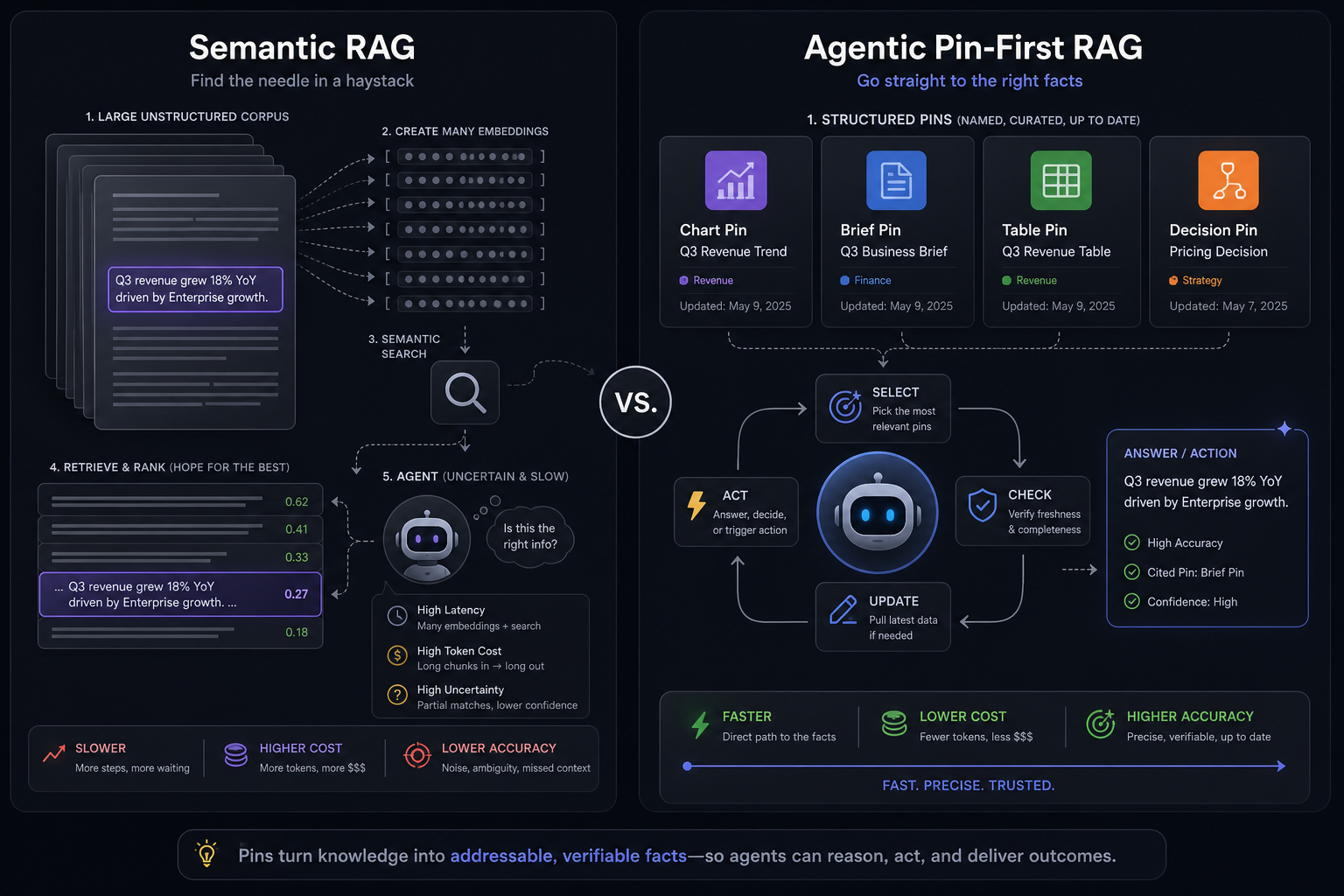
The tradeoff
Semantic search is good at finding related language. Agentic work needs more: the right object to inspect, update, reuse, and share.
Pindown takes a product tradeoff: it invests in structured pins up front instead of treating every workspace surface as raw text. That can add structure and UI work compared with dumping everything into documents. The payoff is not that this is universally "more accurate"; it is that the retrieval model fits the product's thinking in pins. Agents get clearer units to inspect, update, combine, and share.
That is the point of the atomic approach: Pindown was designed for this from the start. Pins are not retrofitted chunks; they are the native objects the agent can find, inspect, update, combine, and share.
Semantic RAG vs pin-first RAG
| Dimension | Semantic/document RAG | Agentic pin-first RAG |
|---|---|---|
| Best fit | Fixed datasets, archives, document snapshots. | Continuously changing workspaces and agent workflows. |
| Latency | Fast for lookup once the index is ready. | Often higher latency because the agent may inspect, verify, and decide before acting. |
| Cost | Embedding/index cost plus retrieved context tokens. | Often higher per task because agentic loops use more reasoning/tool steps, even if they reduce constant re-embedding pressure. |
| Retrieval shape | Similar chunks can be ambiguous, stale, or duplicated. | Pins carry type, title, metadata, permissions, and workspace context. |
| Agent action | The agent sees text and infers what to do. | The agent can act on a targetable pin: update, reuse, share, transform. |
Why pins fit the agentic loop
In Pindown, a pin is already a focused unit of information. It has a type, title, metadata, permissions, location, and relationship to the format it appears in.
That gives the agent a pin-shaped working surface:
- Find the Q3 revenue table pin, not a paragraph that mentions revenue.
- Update the pricing decision pin, not every document where pricing was copied.
- Share the customer proof chart pin, not the whole report.
- Reuse the brief pin in a page, showcase, canvas, or project.
Embeddings can still be useful, but they become one retrieval signal among many—not the whole architecture.
The takeaway
Semantic RAG is useful for searching unstructured knowledge. Pin-first RAG is an alternative approach shaped around Pindown's atomic model: the pin as an addressable, verifiable, reusable unit the agent can reason about and act on.